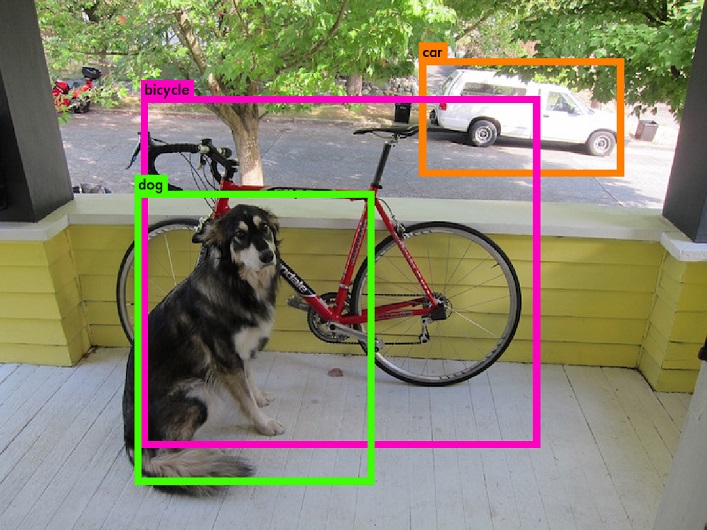
0: Convolutional Layer: 448 x 448 x 3 image, 64 filters -> 224 x 224 x 64 image 1: Maxpool Layer: 224 x 224 x 64 image, 2 size, 2 stride 2: Convolutional Layer: 112 x 112 x 64 image, 192 filters -> 112 x 112 x 192 image 3: Maxpool Layer: 112 x 112 x 192 image, 2 size, 2 stride 4: Convolutional Layer: 56 x 56 x 192 image, 128 filters -> 56 x 56 x 128 image 5: Convolutional Layer: 56 x 56 x 128 image, 256 filters -> 56 x 56 x 256 image 6: Convolutional Layer: 56 x 56 x 256 image, 256 filters -> 56 x 56 x 256 image 7: Convolutional Layer: 56 x 56 x 256 image, 512 filters -> 56 x 56 x 512 image 8: Maxpool Layer: 56 x 56 x 512 image, 2 size, 2 stride 9: Convolutional Layer: 28 x 28 x 512 image, 256 filters -> 28 x 28 x 256 image 10: Convolutional Layer: 28 x 28 x 256 image, 512 filters -> 28 x 28 x 512 image 11: Convolutional Layer: 28 x 28 x 512 image, 256 filters -> 28 x 28 x 256 image 12: Convolutional Layer: 28 x 28 x 256 image, 512 filters -> 28 x 28 x 512 image 13: Convolutional Layer: 28 x 28 x 512 image, 256 filters -> 28 x 28 x 256 image 14: Convolutional Layer: 28 x 28 x 256 image, 512 filters -> 28 x 28 x 512 image 15: Convolutional Layer: 28 x 28 x 512 image, 256 filters -> 28 x 28 x 256 image 16: Convolutional Layer: 28 x 28 x 256 image, 512 filters -> 28 x 28 x 512 image 17: Convolutional Layer: 28 x 28 x 512 image, 512 filters -> 28 x 28 x 512 image 18: Convolutional Layer: 28 x 28 x 512 image, 1024 filters -> 28 x 28 x 1024 image 19: Maxpool Layer: 28 x 28 x 1024 image, 2 size, 2 stride 20: Convolutional Layer: 14 x 14 x 1024 image, 512 filters -> 14 x 14 x 512 image 21: Convolutional Layer: 14 x 14 x 512 image, 1024 filters -> 14 x 14 x 1024 image 22: Convolutional Layer: 14 x 14 x 1024 image, 512 filters -> 14 x 14 x 512 image 23: Convolutional Layer: 14 x 14 x 512 image, 1024 filters -> 14 x 14 x 1024 image 24: Convolutional Layer: 14 x 14 x 1024 image, 1024 filters -> 14 x 14 x 1024 image 25: Convolutional Layer: 14 x 14 x 1024 image, 1024 filters -> 7 x 7 x 1024 image 26: Convolutional Layer: 7 x 7 x 1024 image, 1024 filters -> 7 x 7 x 1024 image 27: Convolutional Layer: 7 x 7 x 1024 image, 1024 filters -> 7 x 7 x 1024 image 28: Connected Layer: 50176 inputs, 4096 outputs 29: Connected Layer: 4096 inputs, 1470 outputs 30: Detection Layer forced: Using default '0' Loading weights from weights/yolo.weights...Done! data/dog.jpg: Predicted in 0.170866 seconds. car: 51% bicycle: 24% dog: 25% init done opengl support available
多测试两张
1
./darknet yolo test cfg/yolo.cfg weights/yolo.weights data/person.jpg
1
./darknet yolo test cfg/yolo.cfg weights/yolo.weights data/horses.jpg
实时检测
运行这个Demo你需要编译 Darknet with CUDA and OpenCV. 你还需要选择 大中小 适当的模型和其对应的权值文件。通过 ls /dev/vi* 查看usb摄像头设备,如果输出video0则证明可用。