Kinect骨骼提取原理
我们给出了从单深度图像中快速准确预测出人体关节3D位置的新方法,且没有使用时间信息。Kinect获取人体骨骼信息的大致原理可以概括为:
1、使用物体识别方法,设计了身体组件的中间层表示,从而将困难的姿势估计问题映射为简单些的逐像素分类问题。2、大型、丰富多样的训练数据集保证了分类器(随机决策森林)估计身体组件时具有姿势、身材、衣着等不变性。3、通过重投影分类器的(身体组件估计结果),我们生成了几个人体关节的可信3D估计。
简介
一些系统通过帧到帧的跟踪获得了很高的速度,但苦于无法快速重新初始化因而不鲁棒。本文中,我们专注于组件的姿势识别:从单深度图像中检测出每个骨骼关节的少量3D候选位置。我们设计了每帧初始化和恢复的技术,以作为任何适当跟踪算法的补充,从而可以进一步融入时间和运动的一致性中。这里给出的算法形成了Kinect游戏平台的核心组件。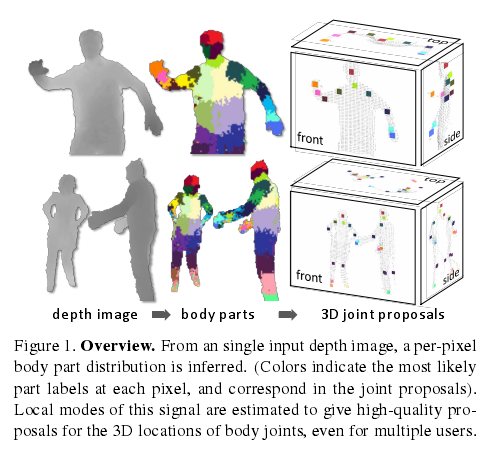
如图1所示,受近来物体识别工作将物体分成多个组件策略启发,我们的方法受两个关键设计目标驱动:
1、计算高效且鲁棒。单幅输入深度图像被分割成稠密概率身体组件标签,组件定义为与感兴趣骨骼关节空间上相近的身体部分。
2、将推理出的组件重投影到世界空间,我们局部化每个组件分布的空间模式,从而形成每个骨骼关节3D位置的带可信权重的预测,可能有几个。
我们将身体组件的分割(从身体分割出各组件)当作逐像素分类问题。对每个像素分别评估避免了不同身体关节间的组合搜索,尽管单个身体组件在不同情形下的外观仍千差万别。我们从运动捕捉数据库中采样出不同身材和体型人物的各种姿势(人体的深度图),然后生成逼真的合成深度图作为训练数据。我们训练出了一个深随机决策森林分类器,为避免过拟合,我们使用了数十万幅训练图像。区别式深度比较图像特征简单产生3D变换不变性的同时维持了计算的高效性。为获得更高的速度,可以使用GPU在每个像素上并行运行分类器。推理出的逐像素分布的空间模式使用mean shift计算,由此空间模式给出3D关节的预测。
我们的主要贡献是:使用新颖的身体组件中间表示将姿势估计问题变成了物体识别问题,为低计算代价和高精度从空间上定位感兴趣的关节而设计了这个中间表示。
我们从实验也获得了几个启示:
(i)合成深度训练数据是真实数据的极好代理(代替品);
(ii)用各种合成数据成比例增大学习问题对(获得)高精确性很重要;
(iii)我们基于组件的方法甚至比精妙的确切最近邻方法更通用。
数据
姿势估计研究往往关注克服训练数据缺乏的技术,这是因为两个问题。第一,使用计算机图形学技术生成逼真的强度图像往往受限于衣服、头发和皮肤造成的颜色和纹理的极大多变性,从而往往使生成的图像退化为2D轮廓。尽管深度摄像机极大地减小了这种困难,仍然存在相当可观的身体和服装shape变化。第二个限制是合成身体姿势图像需要以动作捕获(mocap)的数据作为输入。尽管存在模拟人类运动的技术,却无法模拟人类的所有自主运动。
深度成像
深度摄像机较传统强度传感器有几个优势:工作光强水平低,提供校准后的尺度估计,具有颜色和纹理不变性,解决了姿势的轮廓模糊问题。它们还极大简化了背景减除操作,本文我们将这一点作为前提之一。对我们的方法更重 要的是,我们可以直接合成人物的逼真深度图像,从而可以轻易的建起大型的训练数据集。
运动捕捉数据
人体可以做出很多姿势,这些是很难模仿的。因此,我们捕获人类运动构成一个大型运动捕获(mocap)数据库。我们的目的是包含人们在娱乐场景下所能做的所有姿势。数据库包含几百段内容为驾驶、跳舞、踢、跑、和导航菜单等的视频序列的约500k帧图像。
我们希望我们半局部的身体组件分类器多少能推广到未见过的姿势。特别的,我们并不需要记录不同肢体的所有可能组合;实际上已证实较多的各种姿势已经足够了。进一步的,我们不需要记录运动捕获(mocap)关于垂直轴的旋转变化、左右镜像、场景位置、身材和体型、或摄像机位置,所有这些都可以(半)自动添加。
因为分类器没有使用时间信息,我们关注静止的姿势而不是运动。通常,一macap帧到下一帧之间的姿势变化小得可以忽略。因此,我们使用“最远邻(furthest neighbor)”聚集[15]从初始mocap数据中除去大量相似、冗余的姿势,“最远邻”聚集将姿势p1和p2之间的距离定义为,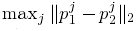 即身体关节j的最大欧氏距离。我们使用100k姿势的子集以确保任何两个姿势之间的距离不小于5cm。
即身体关节j的最大欧氏距离。我们使用100k姿势的子集以确保任何两个姿势之间的距离不小于5cm。
为了使用尚未发现的姿势空间区域提炼mocap(运动捕获)数据库,我们发现必须迭代执行包括运动捕获、从我们的模型采样、训练分类器和测试关节预测准确性的过程。我们早期的实验使用了CMU运动捕获数据库。尽管覆盖的姿势空间远远不够,它还是给出了可接受的结果。
生成合成数据
我们建立了一个随机渲染管道,从中我们可以对全标注训练图像集采样。我们建立该管道有两个目的:真实性和多样性。为使训练出的模型良好工作,采样必须与真实摄像机图像十分相似,并且良好覆盖我们在测试时希望识别的外观多样性。我们的特征对深度/尺度和平移变化都进行了显式处理(见下述),但是其它不变性没能有效编码。因此,我们从(训练)数据学习摄像机、姿势、体型和身材的不变性。
合成管道首先随机采样一组参数,然后使用标准计算机图形学技术从纹理映射3D网络渲染深度和(见下述)身体组件图像。使用文献[4]中的方法,运动捕获重新指向覆盖身材和体型的15个基础网格。在身高和体重上使用的进一步轻微随机变化覆盖了额外的身材可变性。其它随机参数包括mocap帧、摄像机姿势、摄像机噪声、服装和发型。在补充材料中我们给出了这些变化的更多细节。图2比较了管道的各种输出与手工标注的摄像机图像。
人体关节推理和联合
在本节给出我们的身体组件中间表示、描述区别式深度图像特征、回顾决策森林及其在身体组件识别中的应用,最后讨论怎样使用一个模式(mode)发现算法生成关节位置的估计(proposals)。
人体关节标记
本文的一个主要贡献是我们的身体组件中间表示。我们定义了稠密覆盖身体的几个局部身体组件标签,如图2的颜色编码。一些组件定义是用来直接定位感兴趣的特定骨架关节的,其他的是用来填补身体空白或者通过组合来预测其他关节的。我们的中间表示将问题转化成一个能很容易使用高效分类算法解决的问题。在4.3节我们证明了这种转换的惩罚代价很小。
组件在纹理映射中描述,纹理映射融合了渲染时的各种特征。深度和身体组件图像对作为全标注数据来训练分类器(见下述)。本文中的实验使用了31个人体组件:LU/RU/LW/RW头,颈,L/R肩,LU/RU/LW/RW手臂,L/R肘,L/R腕,L/R手,LU/RU/LW/RW躯干,LU/RU/LW/RW腿,L/R膝,L/R踝,L/R脚(Left, Right, Upper, loWer)。明确左右组件使分类器可以区分身体的左右侧。
当然,为适用特定的应用,这些组件的精确定义可以修改。如在上半身跟踪场景中,所有下半身的组件都可以去掉。组件应该充分小以准确定位身体关节,但是也不能太多以免浪费分类器的能力。
深度图像特征
受文献[20]中使用特征启发,我们使用简单的深度比较特征。对于给定的像素x,特征计算如下: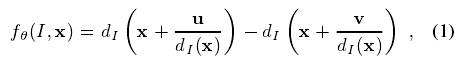
其中dI(x)是图像I在像素x处的深度,参数Ø= (u; v)描述了偏移u和v。使用规范化偏移保证了特征是深度不变的:对身体的一个给定点,无论它离摄像机近还是远,(特征计算)都会给出一个固定的世界空间偏移。特征因此也是3D变换不变的(modulo perspective effects,模型的视角影响)。对背景中或图像边界之外的偏移像素,深度探针将给出一个大的正常数。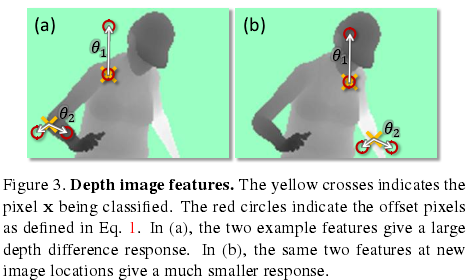
图3图示了不同像素位置x的两个特征。特征(Ø1)对接近身体顶部位置的像素x会有较大正响应,但对较低身体位置处像素点的响应则接近0。而特征(Ø2)将有助于发现细竖直结构,如手臂。
任意单个这样的特征都只能提供关于像素属于身体哪个组件的微弱信号,但是在决策森林中组合起来后,他们就足以准确区分所有训练组件。设计这些特征充分考虑到了计算效率:不需要预处理;(计算)每个特征最多只需要读取3个图像像素和执行5个算术运算;特征(计算)可以直接使用GPU实现。如果采用更大的计算代价,则可以采用潜在的性能更强的基于诸如区域深度积分、曲率的特征,或者使用局部描述符,如[5]中所采用的。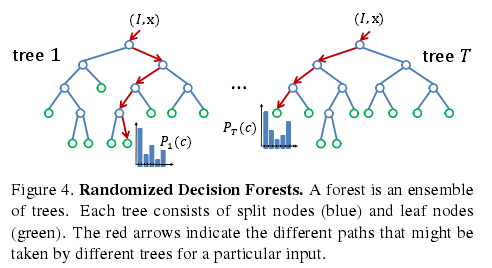
随机决策森林
随机决策树和森林被证实是对于很多任务的快速有效多类分类器,且可以在GPU上高效实现;如图4所示,森林是T棵决策树的总体,每棵树都有分支节点和叶子节;每个分支都包含特征f(Ø)和一个阈值T组成;图像I的像素x进行分类时,从根节点开始不断计算公式1得到特征值,然后根据(特征值)与阈值T的比较结果往左或者往右分支。树T的叶子节点存储了身体组件标签c的训练出的分布。对所有树的分布求平均值并作为最终的分类: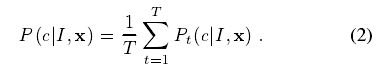
训练
每棵树都在一个不同的随机的合成样本库上训练得到。从每幅图像中随机选择2000个样本像素构成大致在各身体组件上均匀分布的随机子集。
每棵树都使用下面的算法训练:
- 1.随机给出一组(a set of)分支候选(特征参数和阈值);
- 2.使用每个将样本集分成左子集和右子集;
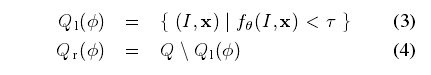
- 3.通过求解最大信息增益问题确定:
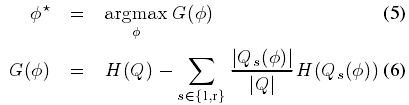 其中香农熵(Shannon entropy)在所有的身体组件标签的规范化直方图上进行计算
其中香农熵(Shannon entropy)在所有的身体组件标签的规范化直方图上进行计算 - 4.如果最大增益仍然很大(足够大),并且树的深度没有达到最大值,则在左右子集和中继续递归。
为降低训练时间,我们采用了分布式实现。在1000个核的集群上从1百万幅图像中将3棵树训练到20层花了大约1天。
联接关节
前述身体组件识别推理出逐像素信息。现在需要将所有像素的这些信息汇聚起来形成3D骨架关节位置的可靠预测。这些预测是我们算法的最终输出,可以在跟踪算法中进行自初始化和从失败中恢复。
一个简单的选择是使用知名的校准深度为每个组件累加概率(分布)团的全局3D中心。然而,无关像素会严重降低这样一个全局估计的质量。因此,我们采用了基于带权高斯核均值转移(mean shift)[10]的局部模式发现方法。
我们定义了如下的(逐个)身体组件的密度估计量: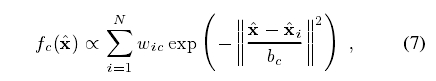
其中是X 是3D世界空间中的坐标,N是图像像素数量,Wic是像素权重,Xi是图像像素xi在给定深度d(Xi)到世界空间的重新投影。Bc是训练出的每个组件的宽度。像素权重同时考虑了在像素上推理出的(属于哪个身体组件的)概率和像素在世界空间中的表面积: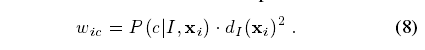
这保证了密度估计是深度不变的,而且使关节预测的准确性有了一个虽小却意义重大的提高。根据身体组件定义不同,可以通过在少数组件集合中预累加得到后验概率P(c|I,x)。例如,在我们的实验中,可以融合覆盖头的四个身体组件来定位头关节。
使用mean shift在这个概率密度(估计)中高效发现模式。对于组件c,我们训练出一个概率阈值λc,所有概率高于该阈值的像素都作为(mean shift)的起始点。当像素权重之和达到每个模式(mode)时就得到了最终的可信估计。这被证明比采用模态密度估计更可靠。
检测出的模式(实际上)位于身体的表面。因此,使用训练出的z偏移将每个模式还原到现场(即身体表面)从而产生最后的关节位置预测。这个简单高效的方法在实践中工作得很好。宽度Bc,概率阈值λc,和表面到内部的z偏移都在一个保留的5000幅图像的验证集中使用网格搜索(grid search)优化。(As an indication,得到的平均宽度为0.065m,概率阈值为0.14,z偏移为0.039m。)
实验
本节描述评估我们方法性能所进行的实验。我们给出了在几个具有挑战性的数据集上的定性和定量结果,并与最近邻方法和当前最高水准[13]进行了比较。在补充材料中我们给出了进一步的结果。除非特别指明,以下的参数都是如下都是这样设置的:3棵树,20层深,每棵树使用300k幅训练图像,每幅图像2000个训练样本像素,2000个候选特征θ,每个特征50个候选阈值τ。
定性结果

图5给出了我们算法的一些例子推理。请注意,在很大的身体和摄像机姿势、景深、cropping(裁剪)、身材和体型(如瘦小的小孩和壮硕的成年人)变化范围上都有很高的分类和关节预测准确性。底部一列给出了身体组件分类失败的一些形式(modes)。第一个例子是没能区分出深度图像中的细微变化,像交叉的手臂。常常(就像第二和第三个失败的例子)最可能的身体组件是不正确的,但是在分布P(c|I,x)中还是有足够多的正确概率团可以生成准确的(关节)预测。第四个是没能很好推广到未见过的姿势的例子。但是(设置好的)置信度防止了(gates)很差预测的出现,以再现率(recall)的损失为代价维持了高的精确性。
注意我们没有使用任何时间或运动约束。尽管如此,补充材料中视频序列每帧图像的结果表明几乎每个关节都被准确预测,且抖动惊人的小。
分类准确度
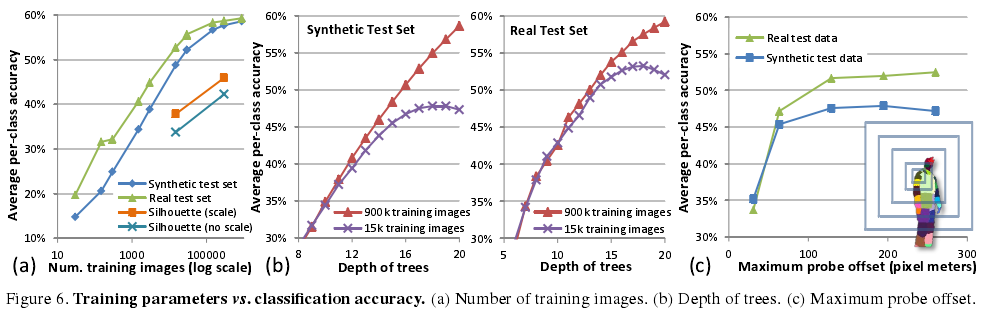
我们研究了几个训练参数对分类准确性的影响。在合成测试集和真实测试集上的趋势高度相关,并且真实测试集一致地显得比合成测试集更“容易”,也是是因为其中的姿势变化少些。
训练图像数量
在图6(a)中,我们展示了准确性大约与随机生成图像数量之间呈对数关系,尽管训练图像增加到大约100k幅时准确性开始停止提高。下面就会展示,这种饱和很可能是3棵20层决策树构成的森林本身模型能力有限所致。
轮廓图像
图6(a)也给出了我们的方法在合成轮廓图像上表现出来的品质。在合成轮廓图像中,式1所计算出来的特征可以是带尺度(以平均深度度量)的、也可以是不带尺度的(固定深度)。采用2D衡量标准设定10像素真正(true positive)阈值,对应的预测准确性分别是:有尺度的为0.539mAP,不带尺度的为0.465mAP。尽管深度模糊明显使预测更艰难,这些结果仍表明了我们方法对其他图像形态(other imaging modalities)也有较好的适用性。
树的深度
使用15k和900k幅图像,图6(b)展示了树深度对测试准确性的影响。在所有训练参数中,深度似乎具有最显著的作用,因为它直接影响着分类器的建模能力。只使用15k幅训练图像时在17层左右就出现了过拟合,将训练集增多到900k则避免了过拟合。精度在20层处的较高梯度表明训练更多层能得到更好的结果,当然有附加的较小的计算代价加上较大的额外存储代价。从实用方面看,感兴趣的是,直到大约10层,训练集的大小关系不大,这告诉了我们一个高效训练策略。
最大探针偏移
训练时允许的深度探针偏移范围对准确性有很大影响。图6(c)给出了在5k幅训练图像上的比较结果。这里,最大探针偏移(‘maximum probe offset’)指式1中u和v允许赋予的x和y坐标的最大绝对值。图中右侧的同心盒子是5个测试的最大偏移集,使用图像中左肩处的像素对它们进行了较准;最大的偏移几乎覆盖了整个身体。(记得最大偏移随像素的世界深度变化而缩放)。随着最大探针偏移增加,分类器可以使用更多空间上下文来做决定,尽管训练数据不够最终会导致过拟合,精度随最大探针偏移增大而提高,尽管在约129像素大小处就不再增大。
联合预测精度
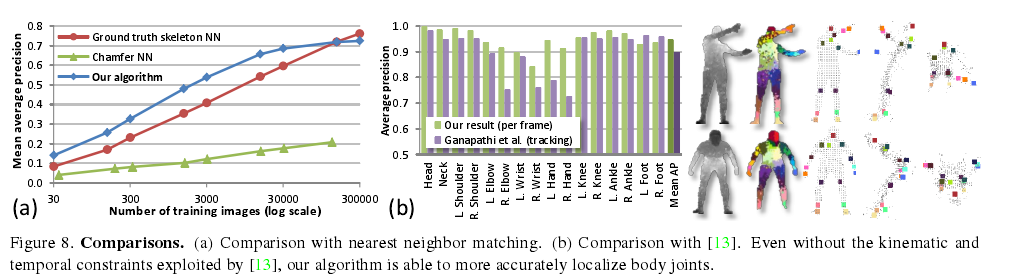
图7给出了在合成测试集上的平均精度,达0.731mAP。我们对比了理想化的配置——即给出了真实身体组件标签的情况和使用推理出的身体组件的真实配置情况。我们确实付出了小小的代价来适用身体组件的中间表示,但是很多关节的推理结果有很高的准确性并且接近(理论上的)上界。在真实测试集上,我们有头、肩、肘和手的真实标签。在这些真实组件上mAP达0.984,而在推理出的身体组件上的mAP也达到了0.914。正如预期一样,在这个较易的测试集上,这些数据理所当然较高。
参考
[1]《Real-Time Human Pose Recognition in Parts from Single Depth Images》-Jamie Shotton Andrew Fitzgibbon,Microsoft Research Cambridge & Xbox Incubation