中间件技术
最早具有中间件技术思想及功能的软件是IBM60年代开发的CICS(Customer Information Control System)。80年代初期,Sun Microsystems开发了一种最早的中间件,座位其开发网络体系结构的一部分,这种中间件是基于RPC协议的,但由于CICS不是分布式环境的产物,而Sun Microsystems开发的不是完整的中间件产品,因此人们一般把Tuxedo座位第一个严格意义上的中间件产品,Tuxedo作为第一个严格意义上的中间件产品,Tuxedo是在1984年由AT&T的贝尔实验室开发完成的。到90年代,中间件技术得到了巨大的发展和广泛的应用,出现了大量具有广泛影响的中间件产品,如OMG的Corba、Microsoft的DCOM/COM+、IBM的MQS等。
中间件是基础软件,处于操作系统(或网络协议)与分布式应用之间,从而屏蔽操作系统(或网络协议)的差异,实现分布式异构系统之间的互操作。目前,对中间件还没形成一个统一的定义,比较公认的IDC的定义是:中间件是一种独立的系统软件或服务程序,分布式应用软件借助这种软件在不同的技术之间共享资源,中间件位于客户机服务器的操作系统之上,管理计算资源和网络通信。
分类
- 消息中间件(MOM:Message-Oriented Middleware)
- 数据库中间件(Database Middleware)
- 远程过程调用中间件(RPC:Remote Process Call):若一台机器的处理能力不能完成相应的计算,需要多个机器协同工作。工作中一台机器读取另一台机器的结果,这之间的数据交换需要一个标准。
- 对象请求代理中间件(ORB:Remote Process Call)
- CORBA即Common Object Request Broker Architecture(公用对象请求代管者体系结构)是一种由公共管理组织(OMG)定义的一种语言无关的面向对象的模型即一种标准。CORBA程序接口包括C++和JAVA两种ORB(Object Request Broker对象请求代理)。一种ORB就是一个库,它能够使得CORBA对象与其它的ORB进行沟通与定位。
- 事物处理中间件(TP Monitor:Transaction Process Monitor)
- J2EE中间件
软件开发技术的发展
- 基于主机的系统
- 两层的Client/Server系统
- 三层(n层)体系架构(表示层、业务逻辑层、数据层)
- 基于Web的三层(n层)体系架构
企业级应用的要求
- 分布式
- 可移植
- 面向Web体系
- 满足企业计算要求 (一致性、事务性、安全性)
- 好的特性 (可伸缩、可扩展、易维护)
- 遗留系统集成
以上要求需要一个良好的基础架构支持。
什么是J2EE
即Java 2 Platform,Enterprise Edition
Open and standard based platform for developing,deploying and managing n-tier,Web-enabled,server-centric,and component-based enterprise applications
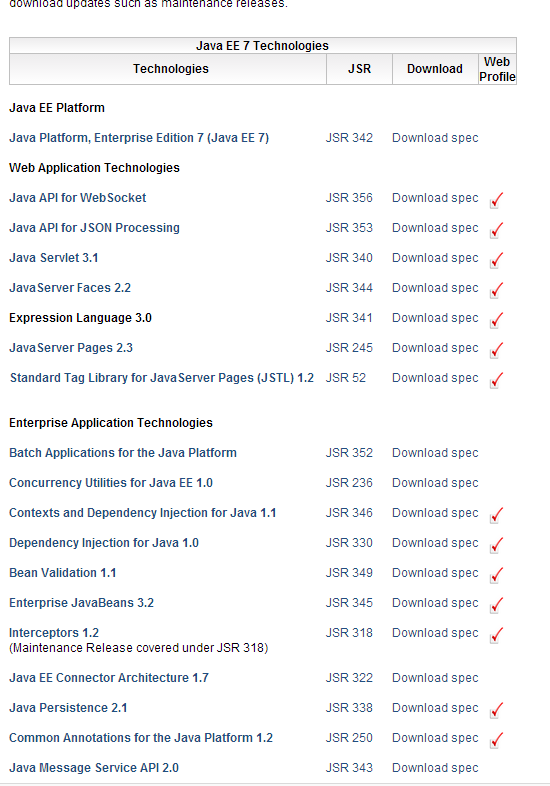
** 运用Java技术开发企业应用的标准,包括了:**
- 多层应用开发模型
- 开发平台-APIs和服务
- 测试软件包
- 参考实现
- 将所有企业技术集合在一个体系结构下的平台
- 特定版本下的EJB,Servlet,JSP
- Java Web Server
- JNDI,JDBC,JTA,JMS,JavaMail,CORBA……
J2EE可以为开发者和用户带来:
- 更短的开发时间(可重用的组件、JSP、EJB)
- 自由的选择(基于开放的标准)
- 简化的连接(XML JDBC RMI-IIOP Web-Service)
J2EE技术架构
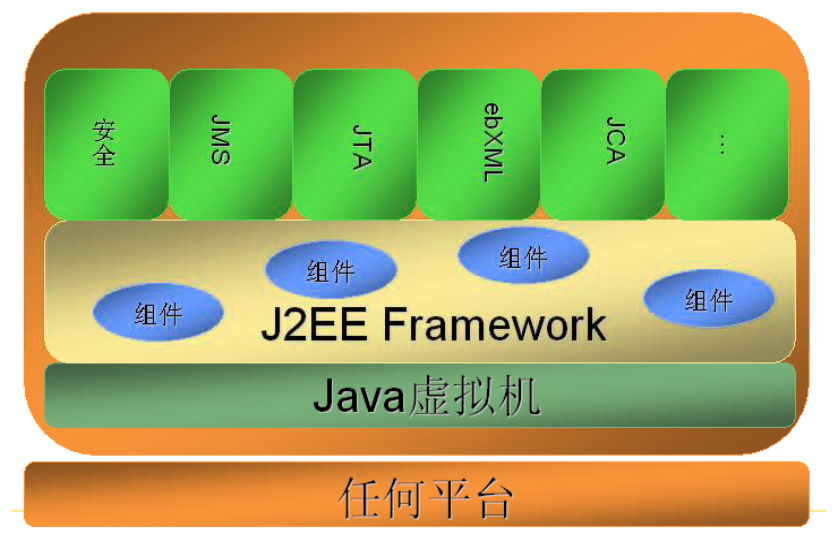
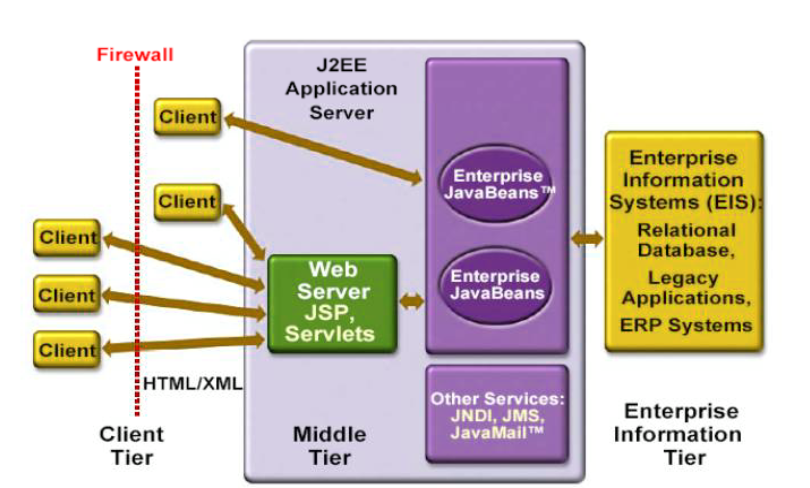
J2EE 主要技术概览
- 展示层-Servlet/JSP
- 中间层-EJB
- 中间层可用的企业服务( 事务服务
、目录服务 、消息服务 、异步组件 ) - 数据层-JDBC
- 远程调用 RMI-IIOP
- 使用现有资源-JCA
Hibernate
Hibernate是一个开放源代码的对象关系映射框架,它对JDBC进行了非常轻量级的对象封装,它将POJO与数据库表建立映射关系,是一个全自动的orm框架,hibernate可以自动生成SQL语句,自动执行,使得Java程序员可以随心所欲的使用对象编程思维来操纵数据库。 Hibernate可以应用在任何使用JDBC的场合,既可以在Java的客户端程序使用,也可以在Servlet/JSP的Web应用中使用,最具革命意义的是,Hibernate可以在应用EJB的J2EE架构中取代CMP,完成数据持久化的重任。
POJO(Plain Ordinary Java Object)简单的Java对象,实际就是普通JavaBeans,是为了避免和EJB混淆所创造的简称。
使用POJO名称是为了避免和EJB混淆起来, 而且简称比较直接. 其中有一些属性及其getter setter方法的类,没有业务逻辑,有时可以作为VO(value -object)或dto(Data Transform Object)来使用.当然,如果你有一个简单的运算属性也是可以的,但不允许有业务方法,也不能携带有connection之类的方法。
Hibernate Hello
1 | <!DOCTYPE hibernate-configuration PUBLIC "-//Hibernate/Hibernate Configuration DTD 3.0//EN" "http://www.hibernate.org/dtd/hibernate-configuration-3.0.dtd"> |
1 | <?xml version="1.0"?> |
Hibernate的CDRU
(1)映射文件
(2)注解
1 | public class HibernateUtil { |
Hibernate 的OID
Hibernate OID的生成策略
业务主键和代理主键
- (1) native:根据底层数据库对自动生成标识符的支持能力,自动选择用,increment,identity,sequcence
- (2) increment:hibernate的自增长方式
- (3) identity:底层数据库生成
- (4) sequcence:由hibernate根据底层数据库的序列自动生成,适用代理主键
- (5) hilo:hibernate根据hight/low算法来生成标识符,适用代理主键
一对多的映射关系
1 | <many-to-one name="类的成员变量名" class="类名" column="数据表中外键字段名"/> |
Junit Test
1 | @BeforeClass |
多对一的映射关系
1 | <set name="多的成员变量名"> |
inverse属性,查出一个没有关联的,然后set的时候
级联删除
自身一对多
hibernate中四中对象状态
- (1)、临时(瞬态)状态 transient:刚用new语句创建,还没有被持久化,并且不处于session的缓存中。
- (2)、持久化状态 persistent:已经被持久化,并且加入到session的缓存中。
- (3)、删除状态 removed:不再处于session的缓存中,并且session已经计划将其从数据库中删除。
- (4)、游离状态 detached:已经被持久化,但不再处于session的缓存中。
一对一的映射关系
(1)一对一主键关联
1 | <hibernate-mapping package="edu.dldx.hibernate.model"> |
1 | <hibernate-mapping package="edu.dldx.hibernate.model"> |
(2)一对一外键关联
1 | <hibernate-mapping package="edu.dldx.hibernate.model"> |
1 | <hibernate-mapping package="edu.dldx.hibernate.model"> |
多对多
(1)多对多单项关联
1 | <hibernate-mapping package="edu.dldx.hibernate.model"> |
1 | <hibernate-mapping package="edu.dldx.hibernate.model"> |
(2)多对多双向关联
1 | <class name="Role"> |
数据库连接池
访问数据库,需要不断的创建和释放连接,假如访问量大的话,效率比较低,服务器消耗大;使用连接池,可以根据实际项目的情况,定义连接池的连接个数,从而可以实现从连接池获取连接,用完放回到连接池。从而有效的提高系统的执行效率。
1 | <!-- 指定连接池里的最大连接数 --> |
阿里巴巴开发的德鲁伊(Druid)连接池,能够提供强大的监控和扩展功能
https://github.com/alibaba/druid/wiki/常见问题
log4j 日志处理
Log4j是Apache的一个开源项目,通过使用Log4j,我们可以控制日志信息输送的目的地是控制台、文件、GUI组件,甚至是套接口服务器、NT的事件记录器、UNIX Syslog守护进程等;我们也可以控制每一条日志的输出格式;通过定义每一条日志信息的级别,我们能够更加细致地控制日志的生成过程。最令人感兴趣的就是,这些可以通过一个配置文件来灵活地进行配置,而不需要修改应用的代码。
1 | log4j.rootCategory=INFO, stdout , R |
此句为将等级为INFO的日志信息输出到stdout和R这两个目的地,stdout和R的定义在下面的代码,可以任意起名。等级可分为OFF、FATAL、ERROR、WARN、INFO、DEBUG、ALL,如果配置OFF则不打出任何信息,如果配置为INFO这样只显示INFO、WARN、ERROR的log信息,而DEBUG信息不会被显示,具体讲解可参照第三部分定义配置文件中的logger。
1 | log4j.appender.stdout=org.apache.log4j.ConsoleAppender |
此句为定义名为stdout的输出端是哪种类型,可以是:
1 | org.apache.log4j.ConsoleAppender(控制台), |
1 | log4j.appender.stdout.layout=org.apache.log4j.PatternLayout |
此句为定义名为stdout的输出端的layout是哪种类型,可以是:
1 | org.apache.log4j.HTMLLayout(以HTML表格形式布局), |
1 | %m 输出代码中指定的消息; |
二级缓存
缓存是介于物理数据源于应用程序之间,是对数据库中的数据复制一份临时放在内存或者硬盘中的容器,其作用是为了减少应用程序对物理数据源的访问次数,从而提高了应用程序的运行性能。Hibernate再进行读取数据的时候,更具缓存机制在相应的缓存中查询,如果在缓存中找到了需要的数据,则就直接把找到的数据作为结果加以利用,避免了大量发送SQL语句到数据库查询的性能损耗。
Session缓存
SessionFactory缓存(应用缓存),需要第三方支持
EHCache,OSCache,SwarmCache,jBossCache2
什么数据适合放置到二级缓存中:
- 经常访问
- 改动不大
- 数量有限
- 不是很重要的数据,允许出现偶尔并发的数据
1 | <!-- 启用二级缓存 --> |
1 | <cache usage="read-only"/> |